Base64 encoding
This topic discusses how base64 works, and the usage of the padding and non-alphabet characters.
RFC4648 link: https://datatracker.ietf.org/doc/html/rfc4648#section-4
Base64 encodes a binary buffer to ASCII using the following 65 characters for encoding.
Table 1: The Base 64 Alphabet
Value Encoding Value Encoding Value Encoding Value Encoding
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w (pad) =
15 P 32 g 49 x
16 Q 33 h 50 y
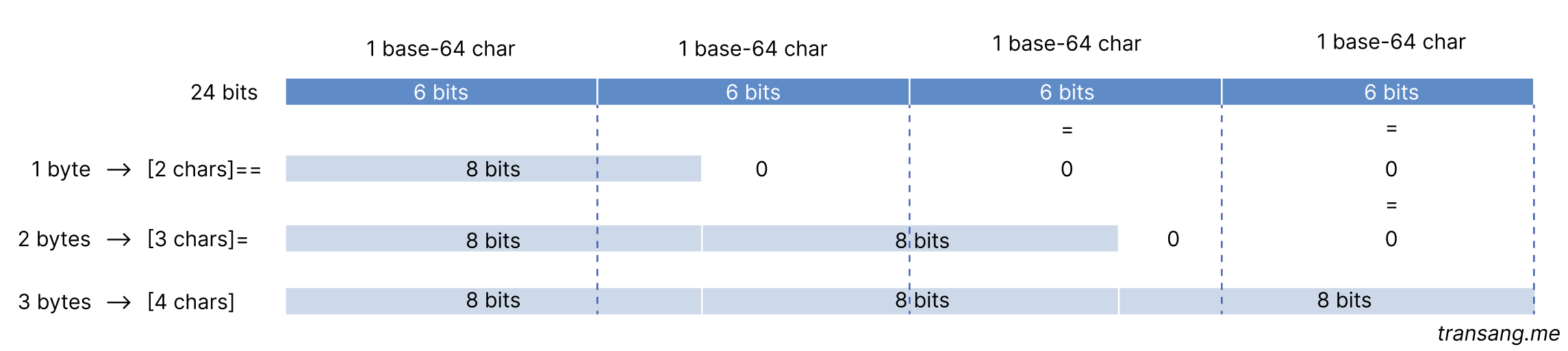
The encoder groups every 3 bytes into a group, equivalent to 24 bits, which then is divided into 4 binary numbers each of 6 bits. Each 6-bit binary number is presented by a character in a base-64 alphabet, hence, the name base64 encoding. The base-64 alphabet includes 65 characters: A-Z, a-z, 0-9, +, /, and =, of which 64 characters are for encoding, and the last for padding.
In some applications, such as in HTTP URLs, the last 3 characters are inefficiently encoded. To avoid inefficient encoding, these characters are usually replaced with non-escaped characters - (for +) and _ (for /) and replaced back when decoding. The padding can be inferred from the encoded length (which will explained in the next section) and can be removed.
To efficiently encode a buffer in Javascript:
const base64 = btoa(buffer).replaceAll('+', '-').replaceAll('/', '_').replaceAll('=', '')To decode a base64-encoded string back to a binary buffer:
const buffer = atob(b64.replaceAll('-', '+').replaceAll('_', '/') + '='.repeat((4 - b64.length % 4) % 4))Padding
If the buffer's length is not divisible by 3, 1 or 2 padding characters (=) are added to the encoded string, when the remainder is 2 or 1, respectively.
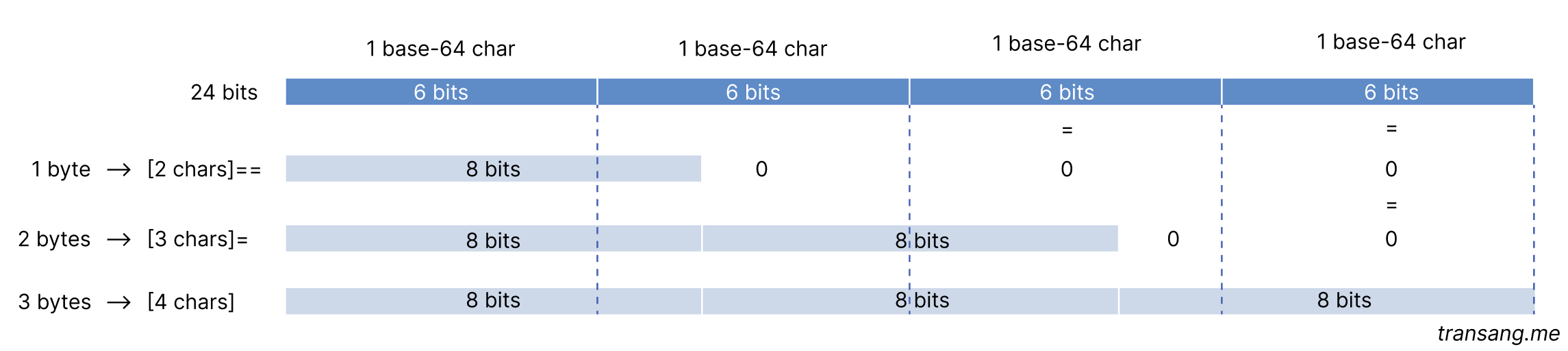
The padding can be omitted when encoding and inferred when decoding as follows:
Check the remainder of the encoded string's length when divided by 4, if the remainder:
- is 1 →invalid.
- is 2 →append 2 padding chars (==).
- is 3→append 1 padding chars (=).
- is 0→do nothing.
Samples:
btoa('a') // 'YQ=='
btoa('aa') // 'YWE='
btoa('aaa') // 'YWFh'atob('Y') // Error: The string to be decoded is not correctly encoded.
atob('YQ') // 'a'
atob('YQ=') // Error: The string to be decoded is not correctly encoded.
atob('YQ==') // 'a'
atob('YWE') // 'aa'
atob('YWE=') // 'aa'
atob('YWE==') // Error: The string to be decoded is not correctly encoded.
atob('YWFh') // 'aaa'The ECMA Script base64-decoding algorithm is described here: https://infra.spec.whatwg.org/#forgiving-base64-decode
